Train small language models without fooling yourself.
Picochat is a from-scratch training factory for 100M-1B class language models with preflight gates, contamination checks, DDP dry runs, crash-safe checkpoints, and a release-readiness dashboard. It is inspired by Andrej Karpathy's nanochat and built around a different product goal: make the factory hard to fool.
Pick the path before the GPU.
Train from scratch.
picochat run tiny owns the full native factory: tokenizer, base pretraining, SFT, optional DPO, eval, and release gate.
Fine-tune an existing model.
picochat train hf-sft starts from a Hugging Face causal LM such as SmolLM and writes HF model folders.
Evaluate and publish evidence.
picochat eval, picochat registry, and picochat serve keep release claims inspectable.
The factory flow
import
train
pretrain
SFT
DPO
score
gate
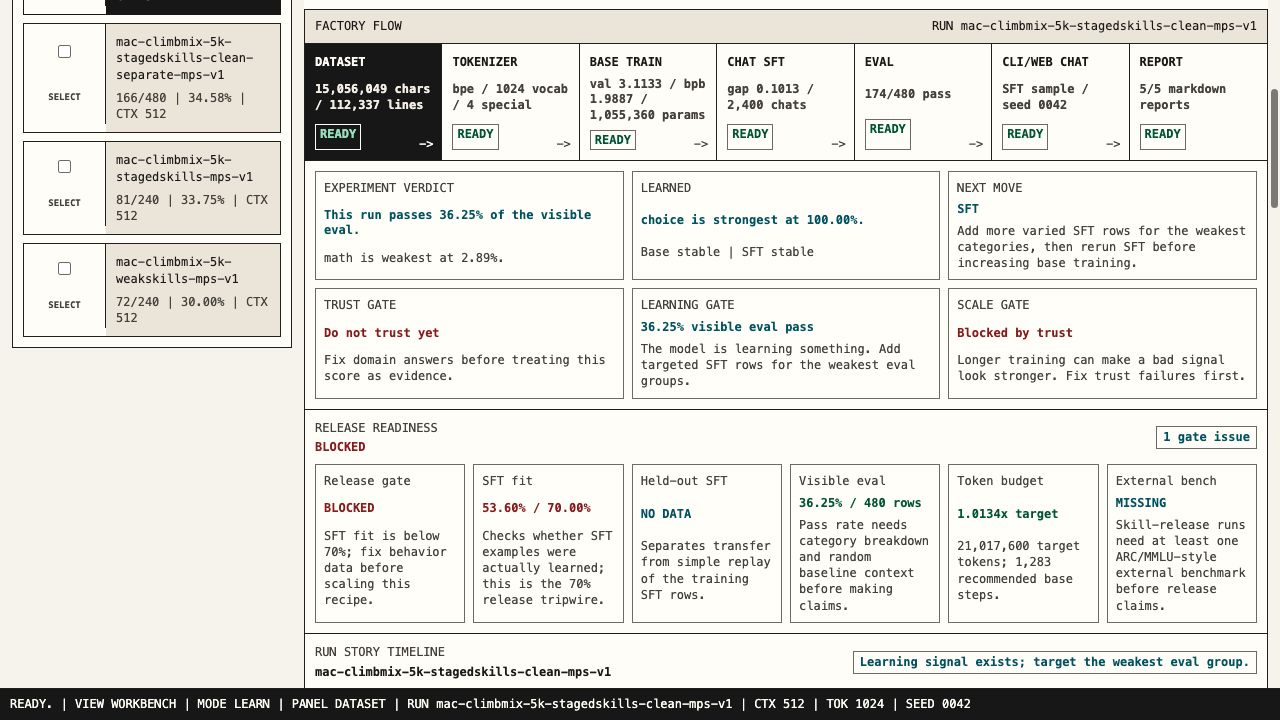
No model claim without a bundle.
The model evidence page tracks what is published, what is pending, and what artifacts a public checkpoint must include.
Preflight can block the run.
Checks token/parameter budget, replay risk, SFT/eval coverage, attention backend, DDP shape, and contamination before GPU spend.
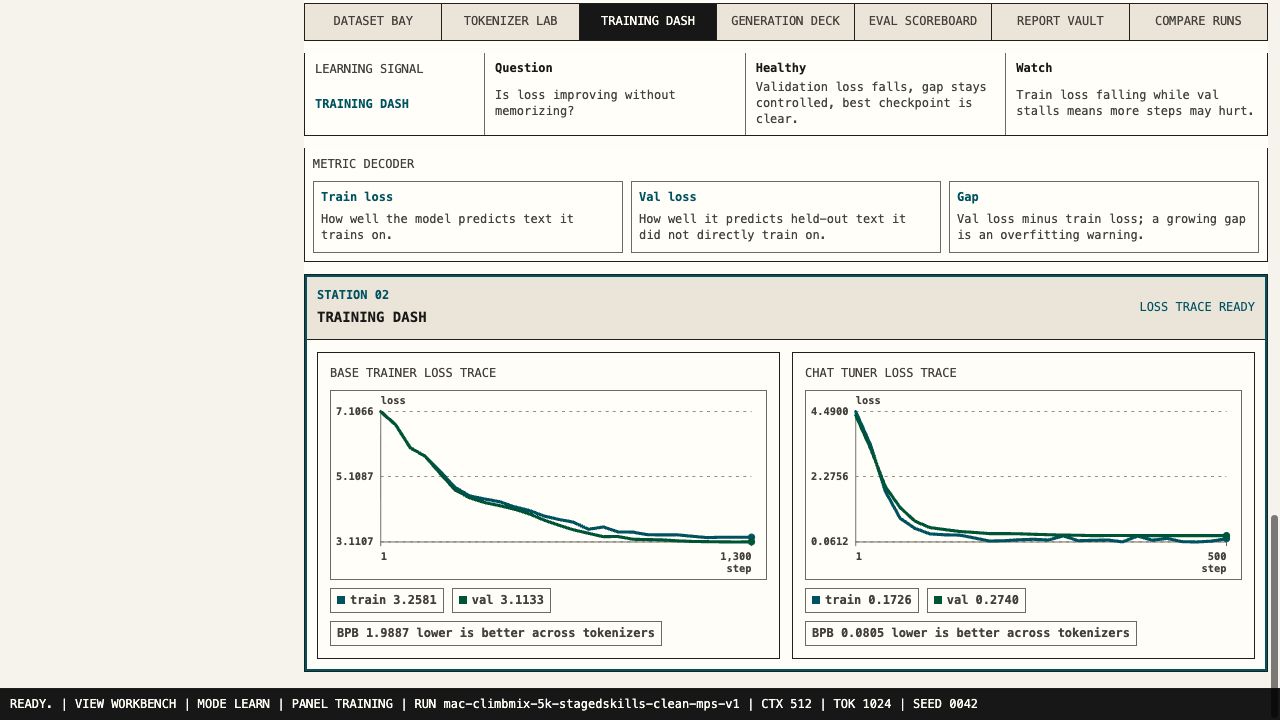
Artifacts stay inspectable.
Crash-safe checkpoints, resume fingerprints, shard SHA256 checks, loss spike warnings, and BPB/loss traces make failures visible.
Completion is not release.
The long-run gate can still block release on SFT fit, held-out fit, visible eval, external benchmarks, prompt echo, or honesty issues.
100M is the first publish target.
The 100M runbook uses a bounded SmolLM-Corpus pack and requires preflight, dry run, eval, release gate, and honesty evidence.
Serve locally before claiming production.
Docker and OpenAI-compatible smoke serving paths make demos repeatable while keeping high-throughput serving limits explicit.
Contributions have guardrails.
CI, pull request templates, and result issue templates keep outside changes tied to tests, docs, and release evidence.
Runs become auditable assets.
picochat registry turns completed runs into a model table and release card with gate, eval, budget, honesty, and checkpoint evidence.
Scale up without guessing.
The Scale Up lane emits remote commands for setup, sanity, ClimbMix or SmolLM-Corpus import, release-skills SFT/eval pack generation, preflight, dry run, full training, bundle, and return inspection.
picochat run tiny \ --scale h100-100m \ --dataset-pack runs/smollm-100m-pack-v1/dataset_pack.json \ --device cuda \ --preflight-only