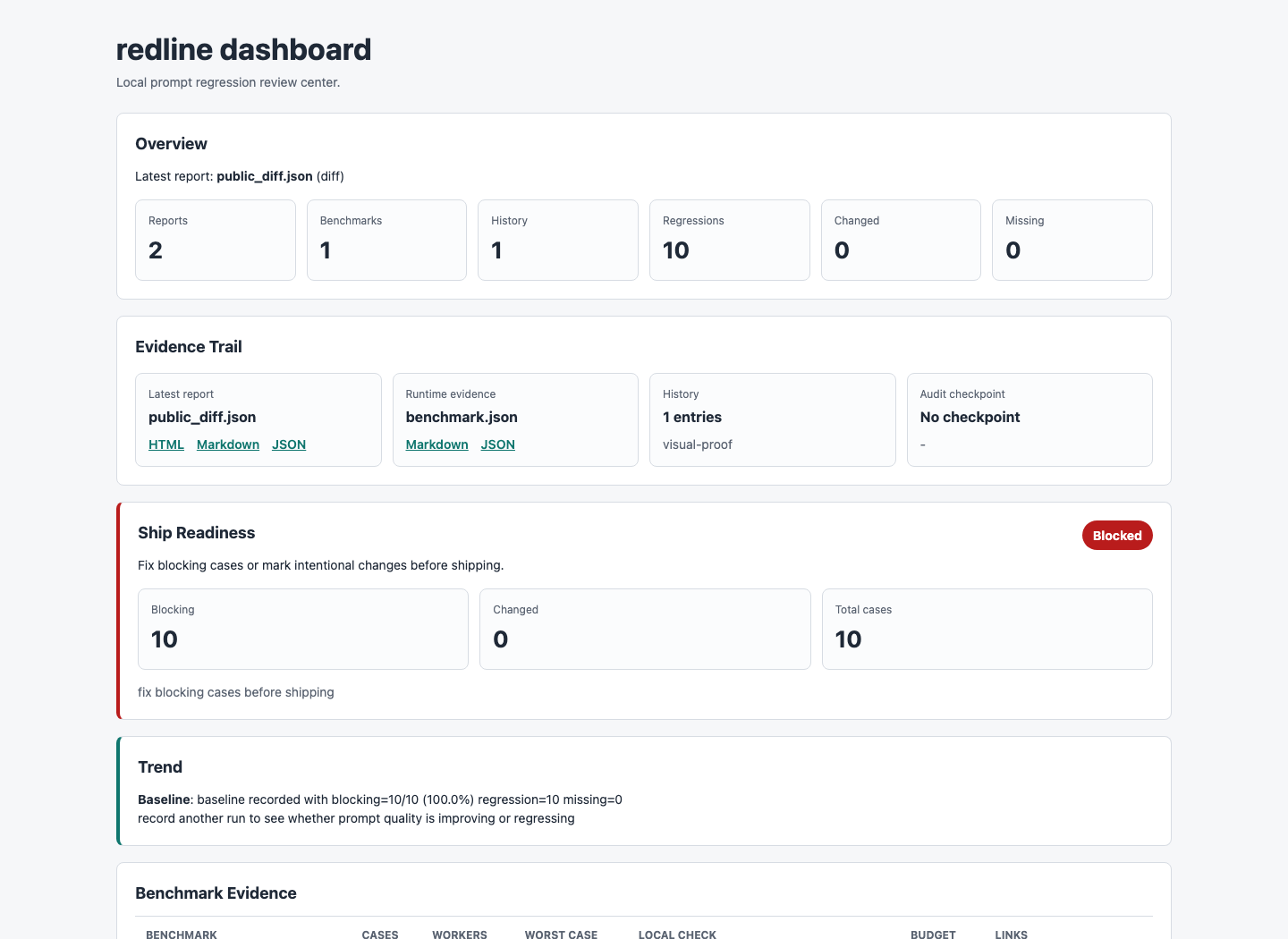
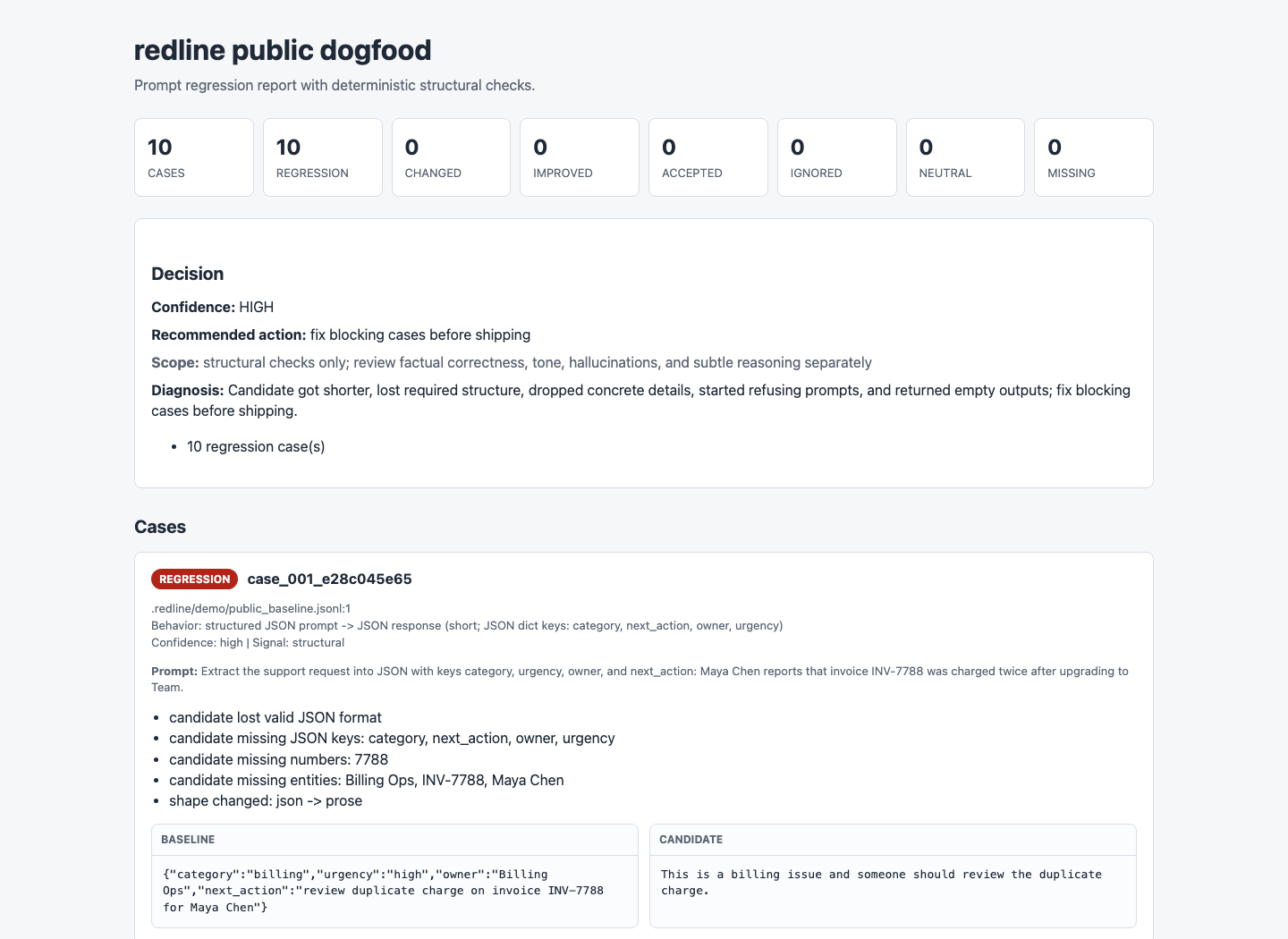
First-run proof
One command for the demo. One public dataset for proof.
The public demo is synthetic and safe to share, but it behaves like
a real prompt change: the candidate gets shorter and silently drops
required structure, dates, owners, URLs, and refusal behavior. The
larger internet dogfood run imports 100 rows from Databricks Dolly
15k and pushes them through the same suite, diff, history,
benchmark, app, and dashboard surfaces.
100 public prompt-response rows
Imported from Databricks Dolly 15k with redline's JSONL importer and kept as local-only dogfood evidence.
20 behavior groups covered
The generated suite covered 100/100 cases and 20/20 deterministic behavior groups.
51 blocking regressions found
The report diagnosed shorter answers, lost structure, dropped concrete details, empty outputs, and substantial content drift.
0 dashboard warnings
The local app loaded 1 report, 1 benchmark, and 1 history entry with no sidecar-artifact noise.